本文書は、Guidelines for Dublin Core Application Profiles(2009-05-18発行)を、国立国会図書館電子情報部電子情報流通課が日本語に翻訳したものです。翻訳監修者は、宮澤彰氏(国立情報学研究所名誉教授)です。
このドキュメントの正式な文書は、あくまでDCMIのサイト内にある英語版であり、この文書には翻訳上の間違い、あるいは不適切な表現が含まれている可能性がありますのでご注意ください。また、リンク先は英語のページですので、予めご了承ください。この翻訳では、日本語としての分かりやすさを優先させたため、一部の訳語については、DCMIメタデータ語彙やアプリケーションプロファイルのためのシンガポールフレームワークで用いたものとは別の訳語をあてている場合があります。又、大幅に意訳した箇所は〔 〕をつけてあります。誤訳、誤植などのご指摘は、国立国会図書館電子情報部電子情報流通課(standardization@ndl.go.jp)までお願い致します。
日本語訳の公開日:2015年7月14日
| 作成者: | Karen Coyle(コンサルタント)〔注1〕 |
|---|---|
| 作成者: | Thomas Baker(DCMI)〔注1〕 |
| 発行日: | 2009-05-18 |
| 資源識別子: | http://dublincore.org/documents/2009/05/18/profile-guidelines/ |
| 置換している: | http://dublincore.org/documents/2008/11/03/profile-guidelines/ |
| 置換される: | なし |
| 最新版: | http://dublincore.org/documents/profile-guidelines/ |
| 文書のステータス: | この文書は、DCMIの勧告である。 |
| 文書の内容記述: | 本文書は、ダブリンコア・アプリケーションプロファイル作成のためのガイドラインを提供するものである。ここでは、ダブリンコア・アプリケーションプロファイルを構成する主要な要素を説明し、プロファイルの開発プロセスを概観する。このガイドラインは、アプリケーションプロファイルの設計者、すなわちメタデータ語彙をある特定の用途のために選択する人を対象としている。アプリケーションプロファイルの機械可読化の方法や、広義のメタデータアプリケーションの設計には触れない。技術的詳細は、参考文献をご覧いただきたい。 |
〔翻訳者注1〕作成者二名の所属は文書発行当時。
メタデータというものは、一つの型を全部に当てはめられるわけではない。実のところ、多数に当てはめられないことも多い。特定のコミュニティやアプリケーションにおけるメタデータのニーズは、それぞれ大きく異なる。そのため、メタデータのニーズを共有しているアプリケーションの間でさえ、様々なメタデータフォーマットが増殖するという状況になっている。ダブリンコアメタデータイニシアチブ(Dublin Core Metadata Initiative: DCMI)は、ダブリンコア・アプリケーションプロファイル(Dublin Core Application Profile: DCAP)という設計用の枠組みを作ることで、この問題に対応してきた。DCAPは、特定のアプリケーションのニーズに応えるとともに、広汎に認められた語彙とモデルに基づいて、他のアプリケーションとの間でセマンティックな相互運用を可能とする。
なお、DCAPは、メタデータレコードを設計するための一般的な道具立てであって、DCMIが定義したメタデータ語彙(DCMI Metadata Terms: DCMI-MT)を用いることは必須ではない。DCAPでは、RDFに基づき定義されたターム(term)は、すべて用いることができる。必要に応じて、複数の語彙から選んだタームを組み合わせてもよい。DCAPは、メタデータレコード(record)のための共通モデルであるDCMI抽象モデル(Dublin Core Abstract Model: DCAM[DCAM])に従っている。
DCAPは、メタデータ作成者のための手引とメタデータ開発者のための仕様からなる。アプリケーションプロファイルは、データが意図していることや、データに期待できることを明確にすることによって、コミュニティ内外のデータの共有やリンク付けを促進する。結果としてそのメタデータは、リンクト・データ(Linked Data [LINKED])、つまりセマンティックウェブの一部となる。そのため、アプリケーションプロファイルの開発チームには、記述される情報資源についての専門家と、その資源を記述するメタデータの専門家、それに加えて、セマンティックウェブやリンクト・データの専門家が入る事が望ましい。
DCAPに基づいたメタデータを、リンクト・データ環境において相互運用可能とするための基盤は、次の各基準である。
〔翻訳者注2〕エンコーディングとは、データを一定の規則に基づいて、表現すること。
DCAPは、特定のアプリケーションで使われるメタデータの記述の仕方を規定する仕様書(集)である。このために、DCAPは、
|
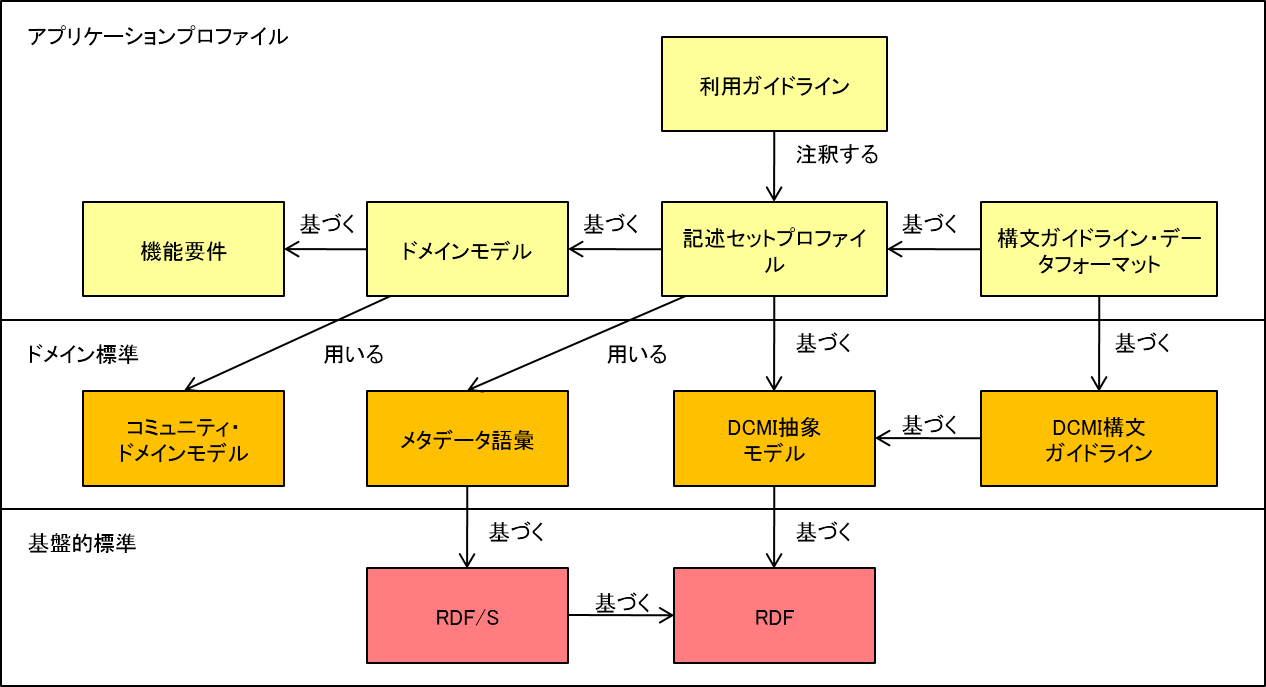
図1―シンガポールフレームワーク |
これらがどのように組み合わされるかは、“ダブリンコア・アプリケーションプロファイルのためのシンガポールフレームワーク(Singapore Framework for Dublin Core Application Profiles)”(DCMI-SF)で示されている(図1)。下層のRDFは、ドメイン標準(domain standards)が拠って立つ基盤的な標準である。中層は、ドメイン標準で、アプリケーションプロファイルを構造的な面やセマンティックな面で安定させるものである。上層は、特定のメタデータアプリケーションのためのデザインとドキュメンテーションである。
シンガポールフレームワークの図の上層をロードマップと見なし、DCAPの作成プロセスを以下の各節において概観する。プロセスの説明のために、著作と著者を記述する単純なアプリケーションプロファイルをサンプルとして使う。このサンプルを“MyBookCase”と呼ぶことにする。
メタデータというものは、何らかの活動をサポートすることを目的としている。その活動に用いられるアプリケーションのために、第一段階として、明確な目標の定義が不可欠である。
機能要件は、すべきこと、しないことを示すことによって、アプリケーションプロファイルの開発をガイドするものであり、アプリケーションプロファイルの開発を成功させるために欠くことができない。アプリケーションプロファイルの開発には、しばしば様々な立場の人々の関与が求められる。サービスの管理者、用いられる資料の専門家、アプリケーションシステムの開発者、サービスの潜在的なエンドユーザが開発に加わるのもよい。
機能要件を作成する際には、ビジネスプロセスモデリング(business process modeling)のような方法論が役に立つ。また、要件を視覚化する方法には、統一モデル化言語(Unified Modeling Language: UML)などがある。特定のアプリケーションのためのユースケースとシナリオを定義することによって、普通なら見落としてしまう機能要件が顕在化することもある。
機能要件を定義するためには、次のような質問への回答を考える必要がある。
機能要件には、特定の活動のニーズへの対応だけでなく、より一般的なニーズへの対応をも含むことができる。理想的には、機能要件は、メタデータ作成者、情報資源のユーザ、アプリケーション開発者のニーズに対応し、その結果としてできたアプリケーションは、コミュニティのニーズを完全にサポートするのがよい。
次に掲げる例は、Scholarly Works Application Profiles[SWAP]の要件である。
オープンアクセスの資料を容易に識別できること。
研究の助成者とプロジェクトコードを識別できること。
機能要件の中には、サポートしなければならない利用者タスクを書き込んでもよい。例えば“書誌レコードの機能要件(Functional Requirements for Bibliographic Records)[FRBR]”にある、以下のようなタスクである。
ユーザの探索基準に合った資料を発見するために、データを用いること。
実体(entity)を識別するために、検索されたデータを用いること。
“MyBookCase”のDCAPにおける機能要件は、次のとおりである。
タイトル検索で本を探し出すためにデータを用いること。
特定の言語に限定して検索すること。
検索された個別資料(item)を出版年月日によってソートすること。
与えられた主題に関する個別資料を発見すること。
著者名と電子メールアドレスを連絡のために提供すること。
機能要件の定義の次は、ドメインモデルの選択、又は開発である。ドメインモデルは、メタデータが記述する事物、それらの事物の関係について、記述するものである。ドメインモデルは、アプリケーションプロファイルを作成するための基本的な設計図となる。
“MyBookCase”のドメインモデルは、“本”と“個人(本の著者)”の二つの事物を持つ。タイトル、言語などのような要素(element)を用いた本の記述方法と、名前と電子メールアドレスを持った“個人”の記述方法を次に示す。“MyBookCase”のドメインモデルは次のように単純である(図2)。
|
図2 |
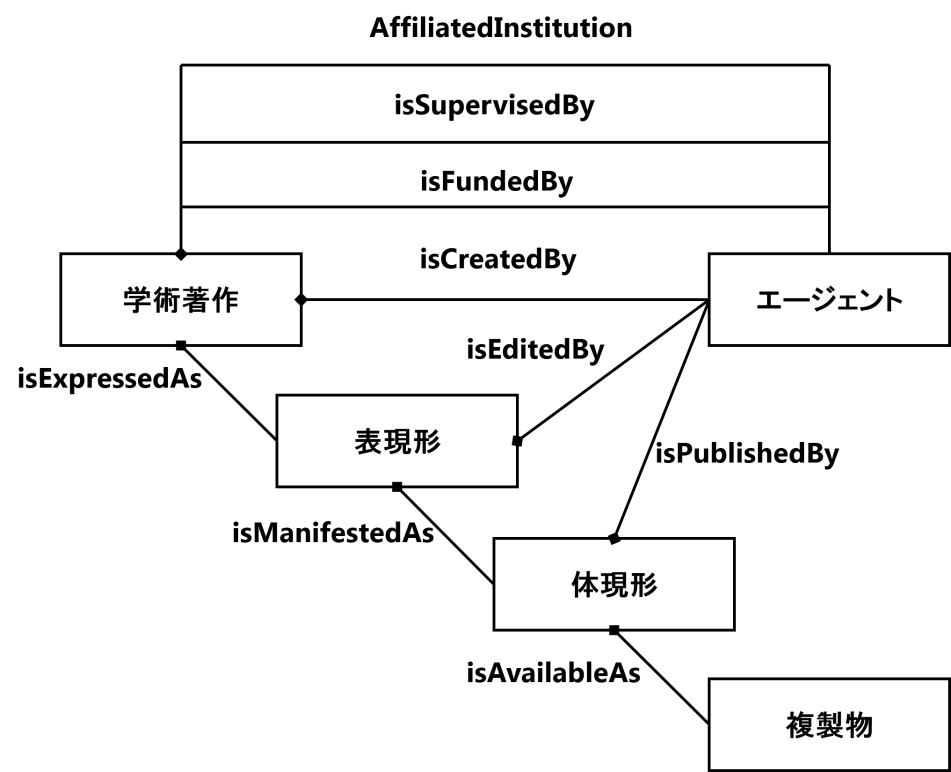
モデルはこれよりも更に単純(例えば、“本”だけ)にすることも、又はより複雑にすることもできる。例えば、SWAPのドメインモデルは、図書館コミュニティのドメインモデルである書誌レコードの機能要件[FRBR]に基づいている。SWAPは、FRBRが定義する実体である“著作(Work)”の代わりに、“学術著作(Scholarly Work)”を定義し、isFundedBy、isSupervisedByなどのような、FRBRにはないエージェントとの新しい関係を導入している。このように、SWAPはFRBRを利用しつつも、特定のニーズを満たすように変更しているのである(図3)。
|
図3 |
メタデータのドメインモデルを定義した後は、そのモデルで事物を記述する際に使うプロパティを選択する必要がある。例えば、“本”はタイトルと著者を持つことができる。著者は名前と電子メールアドレスを持つ“個人”となる。
次の段階は、必要なプロパティについて利用できる既定のものがないか、RDFの語彙を調査することである。既存のプロパティを適切に使えば、より少ない労力でメタデータの相互運用性を向上させることができる。もし必要なプロパティが存在しないならば、付録Cで示したように、独自に定義できる。
“MyBookCase”の単純な例では、情報資源の基本的な記述のためのプロパティに、DCMIメタデータ語彙(DCMI-MT)を用いている。現在開発中のResource Description and Access (RDA)(RDA_ELEMENTS)(RDA_ROLES)には、FRBRに関するより広範なプロパティが準備されている。“Friend of a Friend”(FOAF)の語彙には、人物の記述に有益なプロパティが含まれている。
既存の語彙(vocabulary)のターム(term)が利用できるかどうか評価する際に考慮しなければならないのは、当然ながらタームの定義である。例えば、ダブリンコアのプロパティである“title”は、“情報資源に与えられた名前”と定義されている。もしこの定義がニーズに合うならば、そのプロパティはプロファイルで用いる候補となる。しかし、そのプロパティが特定のアプリケーションに適合するかどうかは、そのプロパティが持つことのできる値(value)のタイプにも依存する。プロパティの値のタイプは、利用したい既存のプロパティが許容する値のタイプと一致しなければならない。
プロファイルで必要となるプロパティでどのような値を用いるか、という課題については、次のような質問の回答を考えることが有益である。あるプロパティについて、回答が“yes”となるのは一つとは限らないことに注意すること。
“MyBookCase”の例を再び見てみると、本のプロパティについての回答は、次のようになる。
上記のような判断は、メタデータの開発プロセスにおいて、付録 Cで説明されているようにデータ要素の技術的モデルを作成する際に用いられる。上記の判断からは、次のデータモデルが導かれる。これは、RDFとDCMI抽象モデルに合致したものとなっている。
著者を個人として記述するプロパティの選択に当たっては、同様のモデルに従う。
これらの結論は次の表に要約される。この表は、付録Cで説明されているプロパティの技術的分析を反映している。行の見出しとなっている用語は、“ダブリンコア抽象モデル”(DCAM)で定義されている。
| プロパティ (Property) |
値域 (Range) |
Value String | 構文符号化スキームURI (SES URI) |
Value URI | 語彙符号化スキームURI (VES URI) |
関係する記述 (Related description) |
|---|---|---|---|---|---|---|
| dcterms:title | リテラル | 可 | 不可 | 不適用[1] | 不適用 | 不適用 |
| dcterms:created | リテラル | 可 | 可[2] | 不適用 | 不適用 | 不適用 |
| dcterms:language | 非リテラル | 可 | 可[3] | 不可 | 不可 | 不可 |
| dcterms:subject | 非リテラル | 可 | 不可 | 可 | 可[4] | 不可 |
| dcterms:creator | 非リテラル | 可 | 不可 | 不可 | 不可 | 可 |
| foaf:firstName | リテラル | 可 | 不可 | 不適用 | 不適用 | 不適用 |
| foaf:family_name | リテラル | 可 | 不可 | 不適用 | 不適用 | 不適用 |
| foaf:mbox | 非リテラル | 不可 | 不可 | 可[5] | 不可 | 不可 |
[1] これらの値は“リテラル”な値域を持つ値に対しては不適用である。
[2] http://purl.org/dc/terms/W3CDTF
[3] http://purl.org/dc/terms/ISO639-2
[4] http://purl.org/dc/terms/LCSH
[5] 電子メールアドレスはmailto: URIを用いて付与することができる。
〔翻訳者注3〕value stringとは、DCMI抽象モデル[DCAM]で定義された、記述セットモデルの構成要素の一つ。
次の段階は、メタデータレコードを詳細に記述することである。DCMIでは、“記述セットモデル(Description Set Model)”(これ自体がDCMI抽象モデル[DCAM]の一部である[付録Aを参照])の中にメタデータレコードを位置づけている。レコードの設計は、記述セットプロファイル(DSP)の制約記述言語を用いて詳細化される。レコードにおける各“記述(Description)”と“文(Statement)”に対し、DSPはテンプレートを定義する。各テンプレートは、要素の繰り返しや許容される値(value)の制約のような、技術的詳細を規定する関連制約条件(constraint)を含む。この節では、“MyBookCase”のための単純な記述セットプロファイルを例示する。
DSPは、ドメインモデルの中の各事物に対して、それぞれ一つずつの“記述テンプレート(Description Template)”からなる。更にその“記述テンプレート”は、対応する事物を記述するプロパティすべてについての“文テンプレート(Statement Template)”からなる。また、これらのテンプレートは、値のタイプ、値の満たすべき要件、値の繰り返しなど、記述又はプロパティ使用の制約条件に関するあらゆる細則を定義する。
“MyBookCase”のDSPは、二つの“記述テンプレート”を持つ。すなわち、“本”に対する“記述テンプレート”と“個人”に対する“記述テンプレート”である。“記述テンプレート”は、“本”又は“個人”の記述に用いられる各プロパティに対して、それぞれ一つずつ“文テンプレート”を持つ。文テンプレートは、プロパティを名前付けするとともに、プロパティ、value strings、語彙符号化スキームなどに対するすべての制約条件を含んでいる。こうした制約条件は、同じ種類の“文”に適用される。
一つのメタデータレコードを厳密に一つの本を表すものとする場合、本の記述は記述セットの中で一度だけ現れる。
DescriptionSet: MyBookCase Description template: Book minimum = 1; maximum = 1
その中で、“本”は一つの(一つだけの)タイトルを持つと決めることができ、そのタイトルというプロパティはURIのhttp://purl.org/dc/terms/titleによって識別される。
“文テンプレート”は、その他のプロパティに対しても作成され、“本”を記述するために用いられる(必要に応じて、出現回数その他の制約が付与される)。
DescriptionSet: MyBookCase
Description template: Book
minimum = 1; maximum = 1
Statement template: title
minimum = 1; maximum = 1
Property: http://purl.org/dc/terms/title
Type of Value = "literal"
Statement template: dateCreated
minimum = 0; maximum = 1
Property: http://purl.org/dc/terms/created
Type of Value = "literal"
Syntax Encoding Scheme URI = http://purl.org/dc/terms/W3CDTF
Statement template: language
minimum = 0; maximum = 3
Property: http://purl.org/dc/terms/language
Type of Value = "non-literal"
takes list = yes
Syntax Encoding Scheme URI = http://purl.org/dc/terms/ISO639-2
Statement template: subject
minimum = 0; maximum = unlimited
Property: http://purl.org/dc/terms/LCSH
Type of Value = "non-literal"
takes list = yes
Value Encoding Scheme URI = http://lcsh.info/
Statement template: author
minimum = 0; maximum = 5
Property: http://purl.org/dc/terms/creator
Type of Value = "non-literal"
defined as = person
上記のプロパティのいくつかは、最少出現回数がゼロである。これは、当該レコードにおいて、これらのプロパティが省略可能であり、たとえこれらのプロパティが存在しなくても、レコードが有効なものとなることを示している。プロパティのいくつかは繰り返し可能であり、例えば言語は三回まで、著者は五回まで繰り返せる。著者は、“個人”としての値を持つもの(defined as = person)として定義したが、これは次のような別の“記述テンプレート”で記される。
Description template: Person id=person
minimum = 0; maximum = unlimited
Statement template: givenName
Property: http://xmlns.com/foaf/0.1/givenname
minimum = 0; maximum = 1
Type of Value = "literal"
Statement template: familyName
Property: http://xmlns.com/foaf/0.1/family_name
minimum = 0; maximum = 1
Type of Value = "literal"
Statement template: email
Property: http://xmlns.com/foaf/0.1/mbox
minimum = 0; maximum = unlimited
Type of Value = "non-literal"
value URI = mandatory
“個人”は、一つの省略可能な姓と一つの省略可能な名を持つことができ、いずれもリテラルの文字列である。又“個人”は電子メールアドレスを持つこともできるが、その電子メールアドレスは接頭辞mailto:付きのURIによって表記しなければならない。多くの人は複数の電子メールアドレスを持つことから、この文は必要なだけ繰り返してよい。
“個人”の記述テンプレートは、メタデータレコードの中で何回でも繰り返し用いてよい。これは、一見すると“本”の記述においては、著者の表記のために“個人”を最大五回まで使用できるという事項と衝突するように見えるかもしれない。しかし、“個人”は他にも用いられる可能性がある(例えば本の主題)。そのため、レコード中の“個人”の記述の出現回数に限度を設けていないのである。
なお、“個人”の記述に含まれるのは、一人分のデータ要素だけである。つまり、著者の文はそれぞれ一人分だけの“個人”の値を持つ。もし著者が二人いるならば、メタデータレコードには二人分の著者に関する文が必要であり、各々の文では一人分を記述する。もちろん、一人の個人が本名とペンネームのように一つ以上の名前を持つこともできるが、メタデータにおいては、複数の著者がいる場合(複数の“記述”が必要な場合)と一人の著者が複数の名前を持つ場合(複数の“文”が必要な場合)を明確に区別しなければならない。
もし、著者の記述に所属機関を含めたいのであれば、著者の“記述テンプレート”と関連付けられる機関の“記述テンプレート”を作成することとなる。この機関の“記述テンプレート”には、機関の名称と場所が含まれる。会社の名称と場所は、所属機関の記述に限らず本の出版者を記述するなど、別の使い方をしても良い。〔注4〕
以上で、“MyBookCase”のための単純な記述セットプロファイルは完成となる。このDSPをXMLでエンコーディングしたものが、付録Bで参照できる。
〔翻訳者注4〕実際には、ここで提示されたような別の使い方をする場合は、ドメインモデルから変更する必要がある。
記述セットプロファイル(DSP)はアプリケーションプロファイルの“what”を定義するのに対し、利用ガイドラインは“how”と“why”を示す。利用ガイドラインは、メタデータレコードの作成者に対して、指示を与えるものである。理想的には、それらは各プロパティを説明し、メタデータレコードの作成時に出てくるであろう疑問に、前もって回答を与える。この文書には、DSPに含まれる情報と重なった部分があるが、より人間が読んで分かりやすい形で示す。メタデータ作成者が知りたいのは“このプロパティは必須か”“繰り返し可能であるか”“このプロパティに使用可能な値(value)は限定されているか”といった点である。これらの情報をメタデータ作成者に提示するためにユーザインタフェースを用いることも、しばしば有効である。例えば、選択すべき値のリストをユーザに示してそこから選択するといったユーザインタフェースがある。
利用ガイドラインには、例えば次のような各種の細則が含まれる。
利用ガイドラインは、比較的単純なものであれば、DSPの文書にプロパティの記述とともに含まれていてもよい。Scholarly Works Application Profilesはその一例で、DSP文書に、手引と説明書が含まれている。
他のコミュニティでは複雑な細則を持っていることもある。細則が長く複雑である場合は、DSPとは別の文書として提示するのが望ましい。例えば、図書館コミュニティでのガイドラインである英米目録規則第二版(AACR2)は、600ページの本となっている。タイトルに関する指示は、多くの章に現れ、多くのページにわたる。これだけの長さのガイドラインであれば、DSPとは別に提示するのが望ましい。
〔翻訳者注5〕こうした語彙には、例えばDCMI Type Vocabularyがある。
この文書に記述されている技術は、シンタックスに左右されない。すなわち、採用する構文は、DCAPで定義されている値と関係とを十分表現できる構文であればよく、特定の機械可読形式にエンコードすることを前提とはしていない。
DCMIは様々なエンコーディングのガイドライン(DCMI-ENCODINGS)を開発してきた。アプリケーションプロファイルの開発者は、これらのエンコーディングを用いて、開発したプロファイルを実働するソフトウェアアプリケーションに載せることができる。DSPは、DCAMへのマッピングが定義されている構文であれば、どのような構文で表現しても良い。DCMIは、DCAMに基づいたメタデータを、HTML/XHTML、XML、RDF/XML形式でエンコーディングするためのガイドラインをこれまで作成してきた。他の形式についても、今後追加される可能性がある。これらの構文でなくても、表現されたデータフォーマットが、基盤的標準(foundation standards)およびDCAMと互換性を持つ限り、使用することが可能である。
ダブリンコアのdescription set〔注6〕は、DCMI抽象モデル(DCAM)の“記述セットモデル”によると、次のような構造を持つ。
〔翻訳者注6〕原文では、DCAMの用語は斜体で表現されている。付録Aの日本語訳では、DCAMの用語は日本語とせず、元の英語のまま用いている。
<?xml version="1.0" encoding="UTF-8"?>
<DescriptionSetTemplate xmlns="http://dublincore.org/xml/dc-dsp/2008/01/14"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dublincore.org/xml/dc-dsp/2008/01/14">
<DescriptionTemplate ID="Book" minOccurs="1" maxOccurs="1" standalone="yes">
<StatementTemplate ID="title" minOccurs="1" maxOccurs="1" type="literal">
<Property>http://purl.org/dc/terms/title</Property>
</StatementTemplate>
<StatementTemplate ID="dateCreated" minOccurs="0" maxOccurs="1" type="literal">
<Property>http://purl.org/dc/terms/created</Property>
<LiteralConstraint>
<SyntaxEncodingScheme>http://purl.org/dc/terms/W3CDTF</SyntaxEncodingScheme>
</LiteralConstraint>
</StatementTemplate>
<StatementTemplate ID="language" minOccurs="0" maxOccurs="3" type="nonliteral">
<Property>http://purl.org/dc/terms/language</Property>
<NonLiteralConstraint>
<VocabularyEncodingSchemeURI>http://purl.org/dc/terms/ISO639-3</VocabularyEncodingSchemeURI>
<ValueStringConstraint minOccurs="1" maxOccurs="1"/>
</NonLiteralConstraint>
</StatementTemplate>
<StatementTemplate ID="subject" minOccurs="0" maxOccurs="infinite" type="nonliteral">
<Property>http://purl.org/dc/terms/LCSH</Property>
<NonLiteralConstraint>
<VocabularyEncodingSchemeURI>http://lcsh.info</VocabularyEncodingSchemeURI>
<ValueStringConstraint minOccurs="1" maxOccurs="1"/>
</NonLiteralConstraint>
</StatementTemplate>
<StatementTemplate ID="author" minOccurs="0" maxOccurs="5" type="nonliteral">
<Property>http://purl.org/dc/terms/creator</Property>
<NonLiteralConstraint descriptionTemplateRef="person"/>
</StatementTemplate>
</DescriptionTemplate>
<DescriptionTemplate ID="person" minOccurs="0" standalone="no">
<StatementTemplate ID="givenName" minOccurs="0" maxOccurs="1" type="literal">
<Property>http://xmlns.com/foaf/0.1/givenname</Property>
</StatementTemplate>
<StatementTemplate ID="familyName" minOccurs="0" maxOccurs="1" type="literal">
<Property>http://xmlns.com/foaf/0.1/family_name</Property>
</StatementTemplate>
<StatementTemplate ID="email" minOccurs="0" type="nonliteral">
<Property>http://xmlns.com/foaf/0.1/mbox</Property>
<NonLiteralConstraint>
<ValueURIOccurrence>mandatory</ValueURIOccurrence>
</NonLiteralConstraint>
</StatementTemplate>
</DescriptionTemplate>
</DescriptionSetTemplate>
アプリケーションプロファイルの設計チームには、RDFに基づくメタデータ設計について、原則を理解しているメンバーを含めるとよい。本付録では、まず、アプリケーションプロファイルにおけるRDFプロパティの選定と使用の際に必要な技術的モデル化の概要を簡潔に説明する。後半では、各プロパティに関する次のような要件と技術的設計との関係を示す。
RDFプロパティは、それが現れる文脈からは独立した一貫性のある方法で、参照および処理されるように設計される。例えば、ダブリンコア要素のタイトルは、ある文脈では本を記述するために、別の文脈では彫刻を記述するために使用できる。このような汎用的に定義された語彙(vocabulary)は、RDFの“文法”に従って正しく使用されている限り、様々な情報源に由来する情報資源の記述(resource description)を整合性のあるデータに統合するための基盤を提供してくれる。
RDFに基づくメタデータで使用できるようにするためには、プロパティは、URIで識別されなければならない。例えば、ダブリンコア要素のタイトルはURI http://purl.org/dc/terms/title(以下dcterms:titleと短縮する)で識別される。これらのURIはどこかで“RDFプロパティ”として宣言および文書化されていることが望ましい。この宣言は、文章で書かれていてもよいが、一般的にはコンピュータ処理用のRDFスキーマでも書かれる。そのRDFスキーマは、 そのURIに使用されるドメイン又はサブドメインの所有者が作成することが最も望ましい。例えば、dcterms:titleのURIは(リダイレクト機能によって)、dcterms:titleがRDFプロパティであることを示すコンピュータ処理用のRDFスキーマ(この文書を執筆している時点ではhttp://dublincore.org/2008/01/14/dcterms.rdf)と結びつけられている。このサブドメインhttp://purl.org/dc/は、ダブリンコアメタデータイニシアチブが(“維持管理”しているという意味で)“所有”している。
メタデータアプリケーションの設計には、多くの理由から、どこかで既に宣言されているRDFプロパティを用いることが望ましい。こうすることで、少なくとも、独自のRDFプロパティを宣言することに関わる余分な仕事に労力を割かずに済む。より重要なのは、周知のプロパティの使用が、他の情報源由来のメタデータとのセマンティックな相互運用性を実現する基盤となることである。しかし、語彙を作成した個々人は、仕事を変えたり、異動したりすることがあるかもしれない。また、研究プロジェクトが中止され、しまいにはサーバが消えてしまうかもしれない。さらに、ドメイン名の所有権もなくなり、それゆえ今日RDFスキーマと結びつけられているURIが十年後には靴の広告と結びつけられている、ということもあり得ると肝に銘じておかなければならない。プロパティは、維持管理に責任を持つことのできる組織が提供するものを用いるのが望ましい。
RDFプロパティは通常、自然言語によって定義されている。アプリケーションプロファイルの設計者は、こうした定義と矛盾のない方法でプロパティを用いるように配慮すべきである。設計者は、(繰り返しなどの)プロパティの使用に技術的制約をかけ、又は特定の目的のために定義を狭義に解釈してもよいが、維持管理者の意図に反するべきではない。
あるプロパティの意図は、自然言語での定義によって汲み取れるだけではなく、与えられたプロパティとその他のプロパティとの公式に宣言された関係によっても汲み取れる。プロパティの定義は、典型的には、正規の“定義域”(プロパティによって記述することのできる事物のクラス)と“値域”(値[value]となることができる事物のクラス)をも規定する。この付加情報は、記述される事物についての推論を可能にし、RDFプロパティの有用性を高める。例えば、プロパティfoaf:img(画像)は定義域にfoaf:person、値域にfoaf:imageを持つため、メタデータを使うアプリケーションは、プロパティfoaf:imgを使用しているメタデータを発見した場合、このプロパティの記述対象は人であり、プロパティによって参照される値は画像であると自動的に推論できる。あるプロパティは、他のプロパティを意味的に細分化したものであってもよい。例えばプロパティdcterms:abstractは、プロパティdcterms:descriptionのサブプロパティであるため、要約(abstract)を持つものはすべて、内容記述(description)を持つということがいえる。
アプリケーションプロファイルの中のプロパティを再利用する際に重要なのは、そのプロパティがリテラルの値を持つことを意図しているか、を調べることである。リテラルの値を持つことが意図されたプロパティは、“リテラル”の値域を持つといわれる。これらリテラルの値とは、オプションとして言語タグ(plain value stringの場合)又はデータ型識別子(typed value stringの場合)をともなう、単一のvalue stringである。“リテラル”の値域を持つプロパティの例には、rdfs:Literalの値域を持つdcterms:dateと、owl:DatatypePropertyであると定義されたfoaf:firstNameがある。〔注7〕“リテラル”の値域を持つプロパティの利点は、その単純さにある。メタデータは値として一つのplain value string又はtyped value stringだけを持ち、メタデータを使うアプリケーションもそれを前提とすることができる。そのため、そのメタデータは単純にエンコーディングと処理ができるようになる。
値域が“リテラル”でないプロパティは、“非リテラル(non-literal)”の値域を持つといわれる。“非リテラル”の値域を持つプロパティの例には、dcterms:LicenseDocumentの値域を持ったdcterms:license、とfoaf:OnlineAccountの値域を持ったfoaf:holdsAccountがある。リテラルの値域を持つプロパティは単純に扱えるのに対して、非リテラルの値域を持つプロパティは柔軟かつ拡張的に処理できる。記述的メタデータにおいて、リテラル値(literal value)は終点となる。例えば、“メリー・ジョーンズ”というvalue stringを出発点として、メリー・ジョーンズという人物に関する付加的な記述をすることはできない。反対に、非リテラル値(non-literal value)は、電子メールアドレス、所属機関、誕生日等、メリー・ジョーンズという人物についての付加情報をいくつでも結びつけられる手がかりを持っている。非リテラル値は、次に掲げる項目を組み合わせて表記できる。
なお、リテラルの値域と非リテラルの値域を持つプロパティの違いは、本来ドメインモデルの設定に関わる問題である。プロパティのタイプによって、メタデータをコンピュータ処理用にエンコーディングする方法、そのメタデータを使うアプリケーションが解釈する方法が決まる。エンドユーザは必ずしも違いを知る必要はない。value stringは、検索結果として表示される場合、リテラル値であるか、非リテラル値に紐づけられているかに関わらず、同一に見える。
既存のプロパティにおいては、値域がリテラルであるか、非リテラルであるかの選択は、通常、公式に定義されている。もし公式の定義が十分でないならば(例えば、dcterms:dateのプロパティは定義上リテラルの値域を持つが、より複雑な値が必要となる場合)、又は必要な意味を持つプロパティが見つからないならば、新しいURIを持ったプロパティを新規に作る必要がある。
〔翻訳者注7〕“リテラル”の値域を持つプロパティの例には、dcterms:dateとfoaf:firstName(タイプはowl:DatatypePropertyとされている)がある。いずれも値域としてrdfs:Literalが指定されている。
ダブリンコアのアプリケーションプロファイルは、プロファイル自体の外部のどこかで定義されているプロパティを“使用する”ことになっている。しかし、もし必要なプロパティがよく知られた既存の語彙の中に見つからないならば、アプリケーションプロファイルの設計者は自身でプロパティを宣言しなければならない。
新しいプロパティを宣言することは、それ自体難しい仕事ではない。名称を与え、定義を明確にし、リテラル/非リテラルのどちらの値域を持つのか決定し、アクセス可能な(そして、例えばhttp://microsoft.com又はhttp://amazon.deなどではない)名前空間のもとに、プロパティのURIを作ることである。“永続的な”URIを提供するhttp://purl.orgなどのサービスは、そのURIを一時的な場所に置かれたドキュメントにリダイレクトする。これは、DCMIのプロパティでも使用されている。RDF語彙の作成と公開のための手引としては、“Cool URIs for the Semantic Web(COOLURIS)”、the RDF Primer (RDF-PRIMER)、“Best Practice Recipes for Publishing RDF Vocabularies(RECIPES)”がある。ベストプラクティスとしては、DCMIメタデータ語彙(DCMI Metadata Terms: DCMI-MT)、ダブリンコアコレクション記述語彙(Dublin Core Collection Description Terms: CTERMS)、とEprints語彙(Eprints Terms: ETERMS)がある。また、ターム(term)をRDFスキーマで公開することも推薦できる。例としてはDCMIメタデータ語彙(DCMI Metadata Terms: DCMI-MT)とダブリンコアコレクション記述語彙(Dublin Core Collection Description Terms: CTERMS)のスキーマがある。
リテラル又は非リテラルどちらの値域を付与するかは、本質的に、単純さ又は拡張性のどちらを選択するかと同意である。単独のValue stringは、日付(“2008-10-31”)又はタイトル(“風と共に去りぬ”)の記録には十分かもしれないが、著者に関しては、名前以上の記録が必要かもしれない。その可能性がある場合は、非リテラルの値域を付与することが賢明である。例えば著者の場合、非リテラルの値域は、電子メールアドレス、所属、誕生日を付加するための、又はアプリケーション外にある著者の記述を指し示すURIを使用するための手がかりを提供する。非リテラル値は、URIの使用(すなわち、URIを単なる“文字列”としてではなく、“URI”として用いること)をサポートするので、リンクト・メタデータ(linked metadata)-グローバルに有効な識別子を用いて相互参照される記述-という究極の目標を達成するのに非常に重要である。
〔以上の知識を前提に、データ内容の専門家が抱く、どのようなプロパティにどのような値をという質問に答える。〕
自由テキストを用いたいか。“自由テキスト”(すなわち、文字列)は、DCMI抽象モデルの中でValue Stringと呼ばれ、リテラル又は非リテラルの値域を持つプロパティに用いることができる。また、場合によっては、複数のvalue stringを一つの文(statement)で、並列して用いるという要件があってもよい。例えば値を複数言語で表記する場合に使える。ただし、これを実現するには、そのプロパティが非リテラルの値域を持つ必要がある。
自由テキストは、既定のフォーマットに準拠しなければならないか。そうであるならば、Value Stringは構文符号化スキーム(Syntax Encoding Scheme)(データ型)とともに使用することができる。
単一のvalue stringで十分か、又は複数の構成要素を持つ、より複雑な記述が必要か(又は必要となる可能性があるか)。もし、値に対して、単一のvalue string以上のものが必要となるならば、用いられるプロパティは非リテラルの値域を持たなければならない。仮に、定義は合致しているが、値域が異なる既存のプロパティ(例えば、リテラルしか許されないなど)を見つけた場合、そのプロパティを用いずに、定義は同じでも、独自のURIを持ち非リテラルの値域を持つプロパティを新規に作らなければならない。
値を識別するため、又は値の記述を指し示すために、URIを用いたいか。DCMI抽象モデルはValue URIをValue Stringとは別の構成物として定義する。Value URIはリテラルな値の記述には使用できないため、非リテラルの値域を持つプロパティに使用する必要がある。もちろん、URIをValue Stringとして記録することは不可能ではない(つまるところ、URIも一つの文字列である)が、そうすると、アプリケーションは、一般的な文字列から区別する確かな方法がないため、その文字列を識別子として解釈することができない。
統制されたリストから有効な値を選択したいか。これを実現するには以下の方法がある。
一般的にいえば、統制されたリストなどのような、公式に定義された値を用いると、メタデータに厳密さを加え、それによって自動処理に対する適合性を向上させることができる。構文符号化スキームと語彙符号化スキームの適切な使用は、こうした方向性における重要な段階の一つである。その一方で、統制語彙中の個々のタームにURIを付与することは、Simple Knowledge Organization System(SKOS)を用いて次第に行われるようになってきている。例えば、LCSHの“World Wide Web”という概念には最近、http://id.loc.gov/authorities/sh95000541#conceptというURIが付与された。このように統制語彙は次第に“SKOS化”されているので、こうした語彙によって、オープンなウェブ上の複数の情報源を出自とするリソースを見つけ出しアクセスすることが、より容易になっていくであろう。語彙符号化スキームによって、単独のValue StringからVocabulary Encoding Scheme URIを持つValue Stringへ、そしてそこから更にValue URI(Vocabulary Encoding Scheme URIを持つ、又は持たないに関わらず)へ柔軟に移行することができる。